안녕하세요 230719 카카오 Tech meet에 다녀왔습니다!
귀중한 경험을 제공해 준 카카오 임직원 여러분께 감사드립니다.
개발자 서밋이나 ~~ 콘같은것에 많이 지원을 해보았지만, 실제 행사에 다녀온것은 처음인데
생각보다 너무 즐겁고 유익한 시간이었습니다.
짧은 지식으로 모자라게나마 필기내용을 요약하여 블로그에 남깁니다.
혹시 오류나 문제사항이 있다면 댓글로 알려주세요!

1부 app server refactoring 후기
이상우 선생님 (soo님)
간단하게 java로 만든 객체를 리팩터링 하는 이야기를 해주셨습니다.
제가 spring에대한 경험이 없음에도 불구하고, 쉽게 풀어 이야기를 해주셔서 쉽게 이해할 수있었습니다
A. 가변 context class는 신중하게 사용하자
가변 context class는 다른 클래스의 모체가 되는 class입니다.
그런데 이러한 클래스들은 의존성(다른 클래스를 참조) 하는 게 두 개 이상이면 위험하다고 합니다.
가변 클래스의 속성을 변형하고 싶을 땐, 작업을 수행하는 객체가
직접 해당 클래스를 입력받아 속성을 변경시키게 하는 것이 아니라,
업데이트할 값을 return 하는 방식으로 하는것이 좋다고 합니다.
B. 클래스 주입 의존성을 고차함수 의존성으로 바꾸자
- 이 부분은 확실히 이해하지 못했습니다.
클래스를 직접 주입하면, 순환 의존성 (cyclic dependency) 이 생길 가능성이 높다고 합니다.
serviceA, serviceB, serviceC가 서로에게 의존하는 상황을 피하기 위해
클래스 기반 의존성을 고차함수적 의존성으로 변경하였다고 합니다.
리팩터링 전
- serviceA는 serviceB를 주입받아, 내부 메서드에서 serviceB의 메서드를 사용합니다.
public class ServiceA {
@Resource
ServiceB serviceB
public void methodA(integer numParam) {
// serviceB.methodOfB(numParam) 사용
}
}리팩터링 후
serviceA의 내부 메서드에서 매개변수로 serviceB의 메서드를 받습니다.
public class ServiceA {
//serviceB 주입 안함
public void methodInA(integer numParam, Function<integer, integer> methodOfB){
//methodB.apply(numParam) 사용
}
}이렇게 변경하면, 클래스를 실행하는 부분에서 오류가 발생하니 해당 부분을 수정해주어야 한다고 합니다.
저런식으로 클래스 의존성을 함수형 의존성으로 바꿔주면.
ServiceB에대한 의존성이 ServiceA 전체에서, 메서드로 줄어들고,
다른것으로 대체하기도 쉬워진다고 합니다.
리팩터링후 성능저하가 조금 있었지만,production 단계로 넘어가고 나선
성능저하가 발생하지 않았다고 합니다.
C. 정적 코드 복잡도를 줄이는 방법
순환복잡도 (Cyclomatic complexity)와 비순환경로 복잡도 (NPath complexity)에 대해 배웠습니다.
순환복잡도
각 항목별로 점수가 있고, 점수를 전부 다 더해줍니다.
제어문, 분기 없으면 1점
제어문마다 1점, 조건식 안에 논리식마다 1점
- 분기가 바뀌는 코드 존재 시 1점, if() 조건문이나 switch case문 하나당 1점
n-path 복잡도
분기마다 2점을 주며 분기별 점수를 곱합니다.
가능한 분기의 경우의 수가 아니라, 실행되는 분기를 기준으로 계산이 됩니다.
복잡도를 줄이는 방법
함수의 책임을 제대로 파악한 뒤, 분리해내는것이 좋습니다.
복잡도를 줄이는 것이 정답은 아니다.
중첩 조건문을 보호 구분으로 바꾸기를 사용하면
n-path 복잡도는 상승하나, 가독성은 오히려 좋아집니다.
노마드 코더주인장 니코선생님이 자주 사용하는 else 없는 if문이 바로 그것
n-path 복잡도가 단순한코드
if (조건1) {
return;
} else {
if (조건2) {
return;
} else {
if (조건3) {
return;
} else {
}
}
}위의 코드는 else가 조건이 참이면
나머지가 획실히 실행되지 않는다는 보장을 명시적으로 해줍니다.
그래서 경로복잡도가 크지 않습니다.
n-path 복잡도는 높지만 가독성이 좋은코드
if (조건1) {
return;
}
if (조건2) {
return;
}
if (조건3) {
return;
}
return;위의 코드는 else가 없어서 n-path 복잡도가 2 * 2 * 2 = 8로 계산이 됩니다.
인텔리제이 구버전에선 정적 코드 복잡도를 계산하는 기능이 있으나, 현재 deprecated 되었다고 합니다.
소프트웨어 흐름도를 분석하는 새로운 인사이트를 얻었습니다.
flow chart에서 분기가 많으면, 음... 복잡하군.. 이 정도로 생각했었습니다.
그런데 직접적으로 코드내부의 루프와 분기문을 세서 복잡도를 수치로 계산하는
기법이 있다는것이 상당히 흥미로웠습니다.
2부 배치 최적화 팁
김남윤 선생님 (yun 님)
이부분은 제가 지식이 없어서 많이 이해하지 못했습니다.
그래도 차근차근 설명해주셔서 db I/O 성능개선 작업을 할때
어떤부분을 고려해보아야할지에대한 인사이트를 챙길수 있었습니다.
스프링 배치 간단 소개

Job은 Step으로 구성되어 있으며, Step은 reader, processor, writer의 일로 구성되어 있습니다.
| reader | process | writer |
|---|---|---|
| 데이터 읽기 | 데이터 처리 | 데이터 저장 |
| 데이터 가져오기 | 비즈니스 로직 | DB저장 |
대규모 데이터처리: Chunk
엄청 많은(100만 건 정도) 데이터를 처리해야 한다면 한번에 읽어들이는것은
비현실적입니다.
이런경우에는 Chunk unit을 정한 후 해당 개수만큼 데이터를 쪼개서 처리합니다.
for (int i, i< total; i += i + chunk)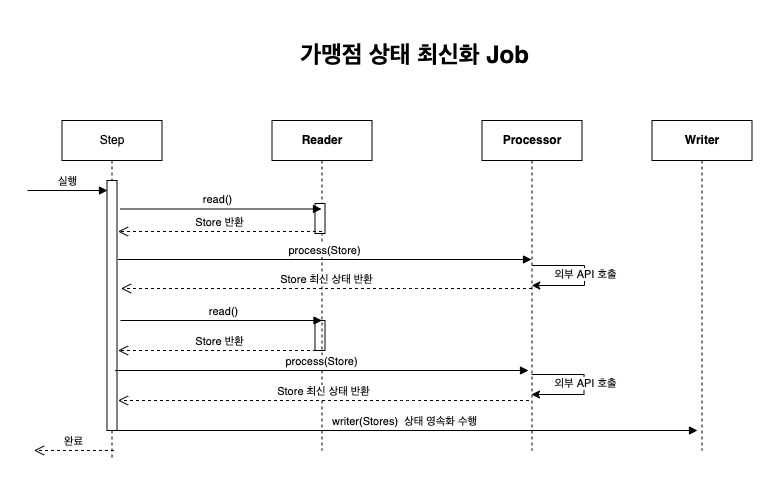
processor가 느린 이유: I/O 처리
- reader: 청크단위로 읽은 데이터를 넘김
- processor: 단건으로처리 후 청크단위로 가공한 데이터를 넘김
- writer: 작성
problem: 각 과정에서 Chunck 단위로 처리를 하므로,
writer는 processor로부터 청크단위 데이터가 넘어올 때까지 기다려야 합니다.
solution: store를 병렬처리한다.
store를 병렬화하고 writer에서 벌크처리하게 만들면 processor의 과정 자체를 삭제할 수 있습니다.
where in 절로 청크사이즈를 한 번에 작업
stores를 group으로 만든 후 where in절을 통해 일괄 업데이트를 해줄 수있습니다.
하지만 이것이 만능은 아닙니다.
- 문제: 새로운 요구사항: 개별데이터 검사 로직 추가
user별 특수 고객점수가 추가 되는 경우 더 이상 group화 하여 일괄 처리할 수 없으므로,
처음으로 돌아가야 합니다
- 해결법: JDBC EXECUTE BATCH 를사용한다
한 쿼리마다 한 청크유닛을 처리할 수 있는 코틀린 프레임워크 Exposed를 사용합니다.
요약
성능 저해 요인별 개선 솔루션 표
| 성능저해 요인 | 솔루션 |
|---|---|
| processor 단건처리 | writer 벌크처리 |
| dirty checking | group, where in |
| 데이터별 개별항목 처리필요: in 사용불가 | Excute 배치 |
핵심은 간단한것 같습니다.
- 결국 성능개선은 I/O 요청을 줄이고, 병렬화로 대기시간을 낮추는 것입니다.
- +@ 병렬처리 같은 필살기를 처음부터 사용하면, 오히려 리팩터링이나 고객 요구사항 충족이 힘들어집니다.
3부 Axile로 개발하면 빨리 끝난다던데
협업과 개인의 성장에 관해 생각해볼수 있었던 주제입니다.
애자일에대한 메타적인 설명과, 애자일 도입상황중 발생하는 문제 해결 방법들을 알려주셨습니다.
간단한 애자일 설명
애자일의 핵심은 변화를 수용하고 대처하는 것이라 합니다.
마치 구글 크롬의 공룡게임처럼요.

(변화에 맞춰 계속 적응해야한다.)
애자일을 도입하는 데에 많은 조건이 필요하지 않습니다.
하지만 역량이 있는 사람들, 확실한 목표, 그리고 에너지 이렇게 3가지는 갖춰져야 합니다.
애자일 도입 협업 과정 중 발생하는 문제점과 대처방안
문제 1. 작업완료에 대한 잘못된 정의
- 나는 이게 작업완료인데, 동료는 아니래요
해결 1. 대화로 해결합니다.
이슈를 추적하고, 기록을 남기며, 일을 시작하기 전에 충분한 대화를 나누도록 합니다.
문제 2. 팀원들이 그들의 일을 모릅니다. 물론 나도 마찬가지입니다.
해결 2. 작업을 시각화하세요.
문제 3. 너무 많은 작업이 진행되고 있어요
해결 3. 무엇이 확실히 진행 중 인지 확인하세요. 작업마다 도구를 정해 시각화하세요.
(무슨 이야기인지 확실하게 이해하지는 못했습니다. 무엇을 하는지 확실하게 인지할 도구가 필요하다는걸까요?
node 작업은 vs코드로.. 파이썬으로 데이터를 작업하는 경우엔 인텔리 J로..?)
문제 4. 우리는 항상 발주기간 deadline을 맞추지 못합니다.
해결 4. 계획을 세우고, 살피고, 계획에 따라 행동하며, 계속해서 수정하세요.
문제 5. 이게 과연 스크럼인지 모르겠어요.
해결 5. 기본으로 돌아가세요
문제 6. 스크럼을 하고 있긴 한데.. 편의에 맞춰 변형하다 보니 능률상승은 없는 거 같아요.
해결 6. 기본으로 돌아가세요
- 투명성, 점검, 적용 3원칙을 잊지 마세요
애자일을 위해 고민할 것
- 우리는 왜, 어디서, 어떻게 일을 시작하는가?
- 고객이 누구인가?
- 목표가 무엇인가?
- 변화에는 항상 이유가 필요하다. - 최근에 프로젝트에서 도입한 변화의 원인이 무엇인가?
- 무엇이 좋았고, 무엇이 나빴는가?
- 회고:팀원이 다 같이 모여 대화를 나눈것이 언제인가?
discussion
각 발표자들의 발표가 끝난 후, 사전 질문과 현장질문에대한 질의응답이 있었습니다.
- 기능구현과 리팩터링 중 우선순위를 어떻게 산정하나요?
- 리팩터링 없이 더 이상의 작업이 어려운 상황이 아니면, 보통 고객의 요구가 우선입니다.
- 리팩터링이 사실 커리어에도 도움이 되고, 유행하는 코드로 바꾸니까 재밌기도 한데 아쉬운 부분입니다.
- 언제 리팩터링을 해야 할까요? tradeoff의 기준은 무엇으로 잡나요?
- 주관적입니다.
- 코드를 읽거나, 수정하거나, 기능의 추가가 어려우면 리팩터링을 우선순위로 하는게 좋습니다..
- 리팩터링 하는 동안 테스트코드가 망가지면 어떡하죠..?
- 언제나 만능 도구가 없다는 걸 기억하세요.
- 리팩터링 후 어떻게 기능이 그대로 동작한다는 것을 검증합니까?
- 프로젝트를 여러 개로 분리합니다. alpha, beta, CBT, production 이렇게 4단계의 검증을 거칩니다.
- 대규모 데이터 배치 중 오류가 발생하면 어떻게 rollback 합니까? 메커니즘은?
- 분리하고, 그룹화하여 단위를 줄입니다.
- 만약 오류발생 시 자동롤백 후 다시 수행하는 로직을 짜면, 성능은 안 좋아집니다.
- 모든 일에는 trade-off가 있습니다.
- 스프링 배치를 위한 환경에는 무엇을 사용하시나요? 높은 가용성은 어떻게 얻습니까?
- 스프링 클라우드 data flow를 사용합니다. scale up을 통해 얻습니다.
- 언제 auto scaling을 합니까?
- (제가 이해를 못 했습니다. scailing이 아마도 메모리나 cpu 갯수같은 자원할당을 조절하는것 같습니다.)
- 애자일 도입이 오히려 일을 만들고, 번아웃을 가져다 올 수도 있지 않나요?
- 애자일 도입으로 추가되어야 하는 일은, 결국 해야 할 일입니다.
- 애자일을 도입하기 위한 consensus를 어떻게 만들어야 할까요?
- 좋은 방향을 설정합니다. 한번에 프로세스를 개선하지말고 step by step으로 조금씩 바꿔가세요.
- 애자일의 매력이 무엇인가요?
- 스크럼에 넣기엔 너무 큰 작업은 점차 일정이 밀립니다. 어떻게 해야할까요?
- 스크럼에 넣기 큰 작업이 없어야 합니다.
- 작업을 더 잘게 쪼개보셔야 할거같습니다.
- 리팩터링을 위한 좋은 테스트 코드 작성법
- 모든 함수를 테스트하는 TDD 방식보단 동작을 테스트하는 BDD 방식이 코드수정을 조금 더 줄여줄 수 도 있습니다.
이 모든 강의내용은 카카오테크의 VOD로 다시 올라온다고 합니다.
좀더 성장하고나서 다시 되새김질을 해보아야겠습니다.
https://www.youtube.com/@kakaotech
kakao tech
카카오테크, 미래의 문턱을 낮추는 기술 Kakao Tech, Lowering the barrier to the future
www.youtube.com
읽어주셔서 감사합니다.
이 글은 아직 주니어도 아닌, 개발자 지망생이 작성한글입니다.
주관적인 해석이나 왜곡이 들어가있을 수 있습니다.
기쁜마음으로 지적을 기다립니다.
'it공부 (이야기)' 카테고리의 다른 글
| 문서여행: 패키지 공식문서에 없는 메서드의 뿌리를 찾아서 / WebSocket, on, 객체지향, 상속 (0) | 2023.03.18 |
|---|---|
| 파이썬으로 타입체크 해보자: Type hint 아닙니다. (타입힌트아님) (0) | 2023.03.15 |
| javascript의 Date모듈의 Month는 0월부터 11월 까지 있다. (0) | 2023.03.14 |
| MDN 문서 여행: fetch()메서드를 이해해보자. /// XMLHttpRequest, Asynchronous, promise, then 그외 무수한 개념들... (1) | 2023.03.10 |